Model Klasifikasi Naive Bayes
Klasifikasi Naive Bayes
(Pertemuan 5 Machinelearning)
Balik lagi nih sobat cerita. Pada kesempatan kali ini aku akan sharing seputar penggunaan klasifikasi Naive Bayes. Wah.. makin banyak pilihan untuk klasifikasi ya pada Machinelearning ini. Jangan khawatir, kita coba bahas secara perlahan., yuk!
Apa itu Klasifikasi Naive Bayes?
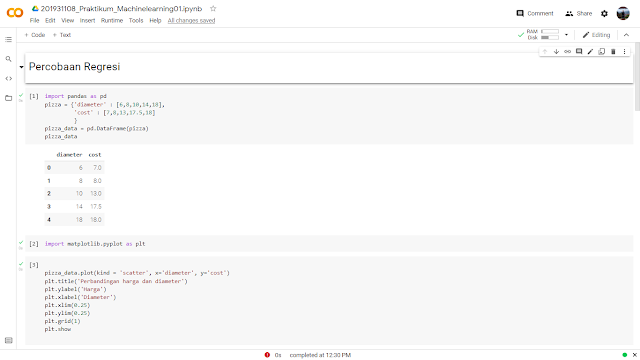
Praktikum Menggunakanbahasa pyhton via google colabs
import pandas as pd
import numpy as npScript di atas digunakan untuk mengaktifkan package pandas dan numpy yang akan digunakan pada tahapan analisis. Package pandas sendiri digunakan untuk pengolahan data yang berkaitan dengan data frame, sedangkan package numpy digunakan untuk manipulasi array secara mudah dan cepat.
# input data
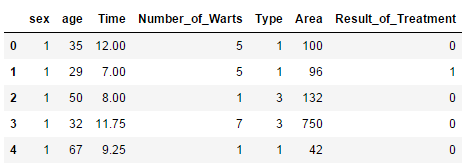
Cryotherapy=pd.read_excel(“Cryotherapy.xls”)# Menampilkan data
Cryotherapy.head()
Selanjutnya digunakan script untuk menginputkan data dari perangkan komputer ke dalam python.
# menampilkan informasi data
Cryotherapy.info()Sebelum melakukan analisis, terlebih dahulu digunakan fungsi “ .info ” untuk menampilkan informasi data yang akan dilakukan analisis. Berikut ini output-nya.

Data yang akan dianalisis memiliki 7 variabel (kolom) yaitu kolom sex, age, number of warts, type, area result of treatment yang memiliki type data integer dan kolom time dengan type data float.
Selanjutnya, digunakan fungsi “ .empty “ untuk melakukan pengecekan apakah terdapat deret data yang kosong.
# Mengecek apakah ada deret yang kosong
Cryotherapy.empty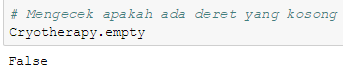
Output menunjukan False artinya tidak terdapat deret yang kosong di dalam data yang akan digunakan.
Selanjutnya digunakan fungsi “ .size “ untuk melihat ukuran data yang akan digunkaan. Setelah melihat hasilnya, ternyata data yang akan digunakan yaitu sebanyak 630 data.
# Melihat ukuran dari data
Cryotherapy.size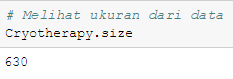
Tahapan selanjutnya yaitu menentukan variabel independen dan variabel dependen dari data yang akan dianalisis. Berikut script yang digunakan.
# Variabel independen
x = Cryotherapy.drop([“Result_of_Treatment”], axis = 1)
x.head()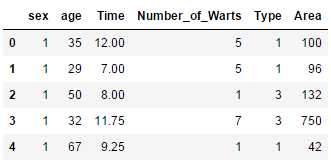
Kolom result of treatment di drop atau di hapus dari data frame karena akan menjadi variabel dependen.
# Variabel dependen
y = Cryotherapy[“Result_of_Treatment”]
y.head()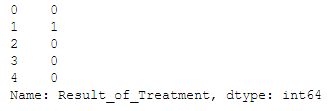
Setelah menentukan variabel independen dan variabel dependen, selanjutnya kan dilkaukan analisis menggunakan klasifikasi Naive Bayes. Pertama dilakukan Train Test Split untuk membagi dataset menjadi training set dan test set.
# Import train_test_split function
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 123)
Script di atas membagi dataset menjadi 80% training set dan 20% test set. Yang artinya dari 630 data, training setakan berisi 504 data dan test set berisi 120 data.
Setalah dilakukan pemisahan, selanjutnya akan dilakukan prediksi pada training set dan test set.
# Import Gaussian Naive Bayes model
from sklearn.naive_bayes import GaussianNB# Mengaktifkan/memanggil/membuat fungsi klasifikasi Naive bayes
modelnb = GaussianNB()# Memasukkan data training pada fungsi klasifikasi naive bayes
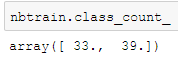
nbtrain = modelnb.fit(x_train, y_train)nbtrain.class_count_
Selanjutnya, digunakan script untuk menentukan hasil prediksi dari x_test
# Menentukan hasil prediksi dari x_test
y_pred = nbtrain.predict(x_test)
y_pred
Untuk menentukan nilai probabilitas dari x_test maka digunakan script berikut ini:
# Menentukan probabilitas hasil prediksi
nbtrain.predict_proba(x_test)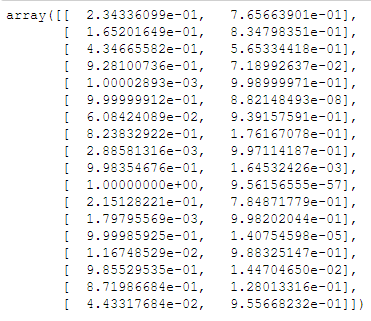
Setelah diperoleh nilai prediksi (y_pred), maka tahapan selanjutnya yaitu melakukan Confussion Matrix.
# import confusion_matrix model
from sklearn.metrics import confusion_matrixconfusion_matrix(y_test, y_pred)

Gambar 10 merupakan hasil confusion matrix, untuk mempermudah dalam membaca, maka digunakan script untuk merapihkan hasil confusion matrix.
# Merapikan hasil confusion matrix
y_actual1 = pd.Series([1, 0,1,0,1,0,1,0,1,0,0,1,1,0,1,1,0,0], name = “actual”)
y_pred1 = pd.Series([1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1], name = “prediction”)
df_confusion = pd.crosstab(y_actual1, y_pred1)df_confusion

Gambar 11 menunjukan bahwa, prediksi traetment dinyatkan gagal dan ternyata traetment gagal sebanyak 7, prediksi traetment gagal dan ternyata traetment berhasil 1, prediksi traetment berhasil dan ternyata traetment gagal sebanyak 2 dan prediksi traetment berhasil dan ternyata treatmen berhasil sebanyak 8.
Karena sebagian besar prediksi dan hasil nya sesuai maka dapat di katakan bahwa tratment cryotherapy baik digunakan unutk melakukan perawatan karena kutil.
Selanjutnya, akan dilakukan perhitungan nilai akurasi
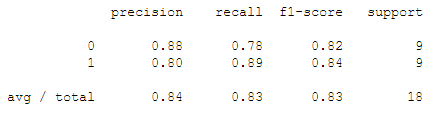
# Menghitung nilai akurasi dari klasifikasi naive bayes
from sklearn.metrics import classification_reportprint(classification_report(y_test,y_pred))
Komentar
Posting Komentar